How did we get to vLLM, and what was its genius?
The age-old tale of wanting to share your inventions with the rest of the world is finally catching speed in the world of LLMs as we race towards an era where consumers can now host their own language models without having to depend on insane amounts of computing power. Here, we will talk about how LLM serving evolved from general model serving, what the challenges were, and how we overcame them.
Let us start by discussing a little about how model serving has evolved through the years.
Pre-2020 Model Serving
The landscape of model serving before 2020 was pretty dry with most of the people serving their machine learning models through different general frameworks, the most notable of which was Flask, since most of the code for ML was being written in Python.
The first real framework dedicated to serving ML models came in the form of TensorFlow Serving by Google, the first commits to which were made in late August 2016. This laid the foundation for most of the frameworks to come, including, but not limited to, Clipper (UC Berkeley), BentoML, TorchServe (Facebook), and HuggingFace’s initial inference API.
All of these frameworks were determined to give the users the ability to create REST APIs for their ML models. However, none of these were LLM specific since LLMs were not being made for consumers just yet.
 Image generated by ChatGPT (Prompt - "Generate an image of an LLM being served in a cartoonish manner.")
Image generated by ChatGPT (Prompt - "Generate an image of an LLM being served in a cartoonish manner.")
The Year That Changed It All - 2020
In June 2020, OpenAI announced a private beta version API of GPT-3. While the model, at the time, only worked as a “text-in, text-out” model, it soon started making waves in the industry since it was the first time that a language model was generating syntactically flawless and coherent text at such a large scale.
Cut to November, OpenAI opened up its API to the general public, which is widely considered a landmark event in the history of AI. For the first time in human history, people were talking to machines, and the machines were replying as if there was a human operating it and writing all the replies.
Post-2020 Model Serving
Suddenly, serving traditional ML models just wasn’t enough, so Cohere and AI21 Labs also came up with their own commercial LLM APIs to challenge OpenAI.
It wasn’t until 2021 that distributed serving came into the picture with Anyscale introducing Ray Serve, which provided a Python-centric approach to building and deploying serving applications.
Following all of this, NVIDIA came into the picture with Triton Inference Server. While not exclusively for LLMs, Triton gained immense popularity as it was highly optimized and supported multiple frameworks, including TensorFlow, PyTorch, and ONNX. Their USP was that they allowed serving multiple models from different frameworks simultaneously while proving features like dynamic batching and model ensembles. Along with Triton, NVIDIA also introduced FasterTransformer in 2021, which was technically a library that provided highly optimized implementations of transformer models for NVIDIA GPUs.
Why Talk About FasterTransformer (FT)?
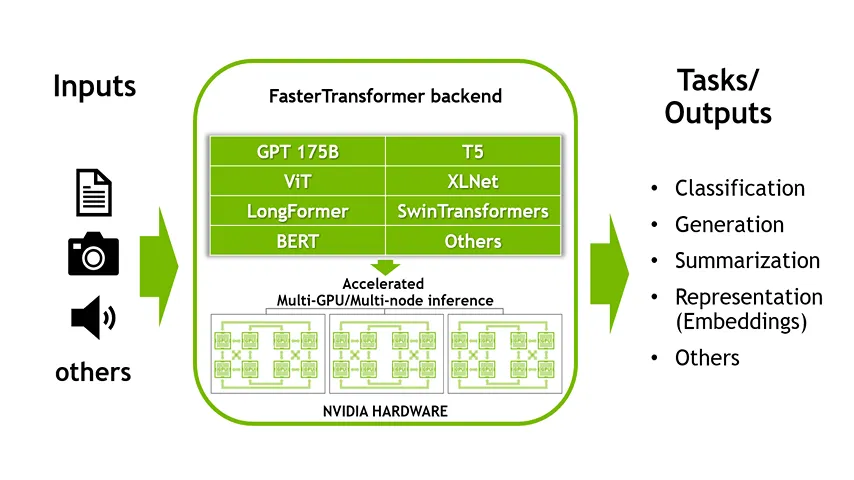 An overview of FasterTransformer (Image by NVIDIA's technical blog - Link can be found in the reference section)
An overview of FasterTransformer (Image by NVIDIA's technical blog - Link can be found in the reference section)
Back when it was released, the unique feature of FT was that it supported the inference of large transformer models in a distributed manner (as shown in the image above). At the time, only tensor parallelism and pipeline parallelism were being used to distribute a model onto multiple GPUs and nodes.
Tensor Parallelism - Instead of performing all the computations on a single GPU/node, the tensor is sliced (either column-wise or row-wise) into smaller chunks and distributed across multiple devices. The output of all of the devices is concatenated in the end. In attention calculation, the computation of the different chunks of the tensor (Q, K, and V matrices) is what defines the multiple heads and facilitates the learning of the model.
Pipeline Parallelism - Splitting the model into different stages and executing each stage on a separate device to minimize the amount of time any particular GPU remains idle.
Here are the other optimizations that FT offered to reduce the latency and increase the throughput,
- Adding a caching mechanism for Key and Value matrices, along with multiple parts of the neural networks.
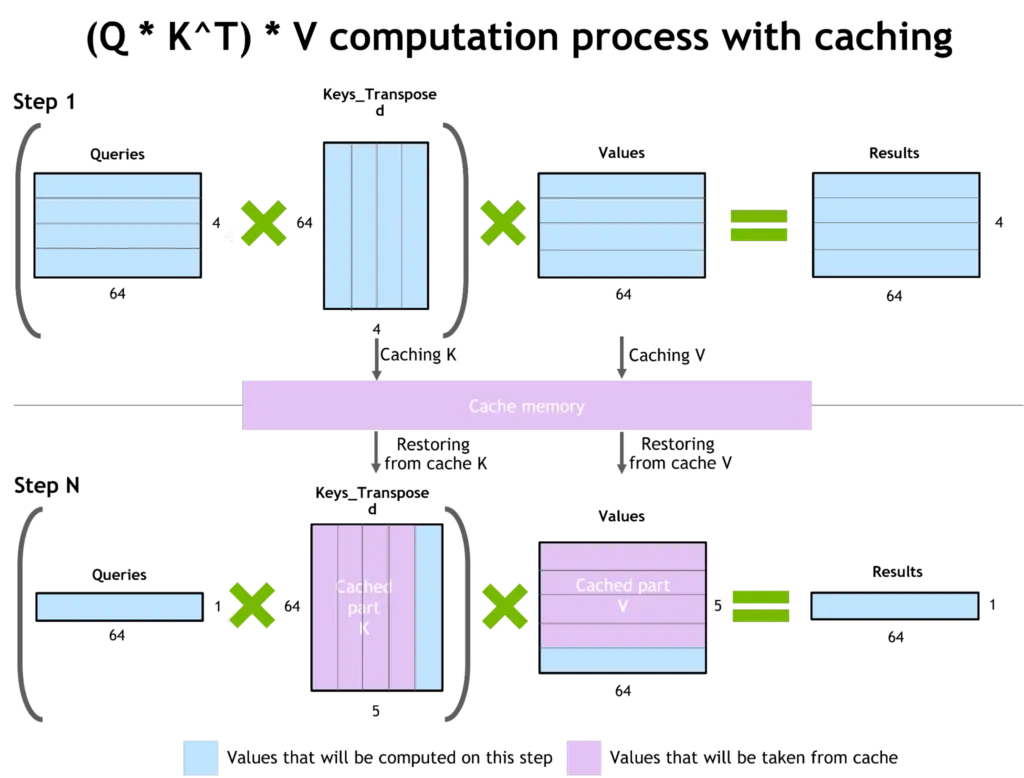 The caching mechanism in FasterTransformer library (Image by NVIDIA's technical blog - Link can be found in the reference section)
The caching mechanism in FasterTransformer library (Image by NVIDIA's technical blog - Link can be found in the reference section)
-
Reuse the memory buffer of activations/outputs in different decoder layers.
-
Inferencing with lower-precision input data (fp16 and int8).
TensorRT had always been NVIDIA’s go-to inference engine that was highly optimized for deep learning models on NVIDIA GPUs. As FT evolved, the tricks that it was using to provide optimization for transformer models started to generalize very well, and NVIDIA soon realized that this library must be tightly integrated with the TensorRT inference engine to prove ever higher throughput on NVIDIA GPUs.
Now, FasterTransformer is a key optimization technique within the TensorRT framework that can be accessed by developers through a plugin.
How Does an LLM Make an Inference?
Before heading into the frameworks, let us spend a quick minute to see how any LLM model makes an inference (we will only be talking about decoder-only LLMs).
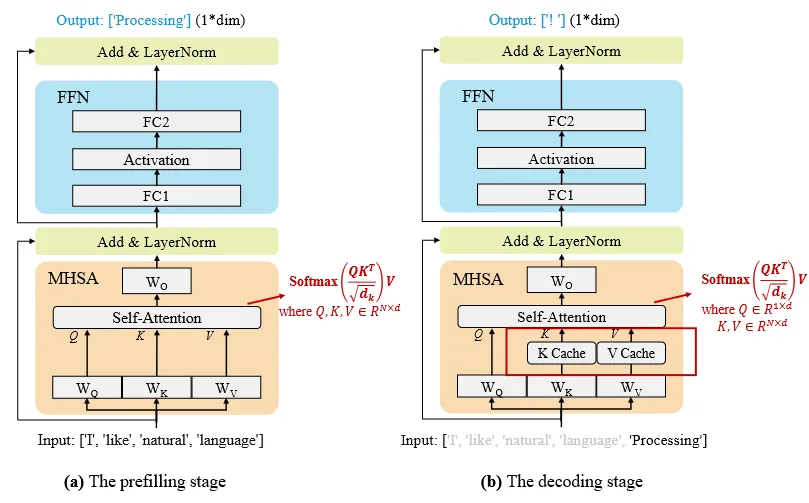 The two stages of the LLM inference process (Image taken from "A Survey on Efficient Inference for Large Language Models" - Link available in the reference section)
The two stages of the LLM inference process (Image taken from "A Survey on Efficient Inference for Large Language Models" - Link available in the reference section)
Let us look at the two stages, one by one,
1 - Pre-fill Stage
In this stage, the complete input text is processed through all the transformer layers, and the model simultaneously captures the relationships between all the tokens in the input sequence. One more thing to note here is that the KV cache is also being created at this stage.
2 - Decoding Stage
The decoding stage takes in the encoded context and the KV cache from stage 1 as input. Additionally, a start token is also provided for the generation. This time around, the attention mechanism only attends to the previously generated tokens. The output generated is basically a distribution over the vocabulary provided to the model, and depending upon the type of sampling being used (greedy or stochastic), an output token is generated (this token is also used to update the KV cache).
This approach helps in explaining the autoregressive nature of decoder-only LLMs along with enabling support for batch computations and streaming the tokens generated by LLMs one-by-one.
The Year of LLM Serving Frameworks - 2023
By 2022, NVIDIA had integrated FasterTransformer with their Triton Inference Server but there was still a tremendous amount of memory that was being wasted.
Then came 2023, with most of the famous LLM serving frameworks that we have today, including vLLM, DeepSeed-Inference, TensorRT-LLM, HuggingFace TGI, llama.cpp, etc. Let us talk about vLLM and see why it became one of the most successful frameworks for serving LLMs.
vLLM - The Genius of PagedAttention
Before we jump into the crown jewel of vLLM - PagedAttention, let us first understand the issues that surrounded LLM serving before vLLM.
Before June 2023, the primary issue in LLM serving was inefficient memory management of the KV cache. As we saw in the FasterTransformer overview, the KV cache is used to avoid recomputing the attention scores for every previous token at every step in autoregressive generation.
At step \(t\), we have \(x(t)\) as the input embedding of the latest token.
Then, \(x(t)\) is appended at the end of the generated sequence,
\[X = X(1), X(2), …, X(t-1), X(t)\]Let \(K(i)\) and \(V(i)\) denote the matrices representing all heads for token i. We then have,
\[\text{K_cache} = [K(1), K(2), …, K(t-1)]\] \[\text{V_cache} = [V(1), V(2), …, V(t-1)]\]Now, in the attention calculation, only the \(q\), \(k\), and \(v\) for the new token need to be computed before computing the attention weights,
\[A = softmax(\frac{QK^{T}}{\sqrt{d_{k}}})\]Here, we only need to calculate \(q(t)\), \(k(t)\), and \(v(t)\) while updating the cache as well.
The Problem - Before PagedAttention, the KV cache was typically allocated as contiguous blocks of memory, i.e., a large, continuous chunk of GPU was reserved for the KV cache of each request.
Therefore, for each request in the model and for each head you needed,
\[\text{memory_per_head_per_layer} = \text{max_seq_len} * \text{d_h} * \text{sizeof(float)}\]where \(d_h\) is the dimension of each head, we are assuming single precision (float).
\[\text{total_cache_memory} = \text{num_layers} * \text{num_heads} * \text{memory_per_head_per_layer} * \text{num_requests}\]This led to the following issues,
1 - Internal Fragmentation: Any sequence shorter than the max_seq would result in a large portion of the contiguous block unused, i.e., memory is wasted inside every allocation.
2 - External Fragmentation: If the GPU memory is fragmented into smaller chunks, a request that needs a large enough contiguous block will be rejected even if the sum of the smaller chunks is greater than the needed space.
3 - Batch Size Limitation: The total number of concurrent requests made was severely limited by the available contiguous memory.
 KV cache memory management before PagedAttention (Image taken from "Efficient Memory Management for Large Language Model Serving with PagedAttention" - Link available in the reference section)
KV cache memory management before PagedAttention (Image taken from "Efficient Memory Management for Large Language Model Serving with PagedAttention" - Link available in the reference section)
vLLM’s solution to the big problem - Introducing non-contiguous, paged memory allocation for the KV cache.
vLLM changed the complete landscape of LLM serving by taking a page out of the books on Operating Systems, essentially the idea of virtual memory and paging. This has esentially allowed Operating Systems to use more memory than is physically available for decades.
In 2023, a team at UCB published a paper titled “Efficient Memory Management for Large Language Model Serving with PagedAttention,” in which they described a method to effectively reduce the wastage in KV cache memory to near zero. In the paper, the authors describe PagedAttention as,
PagedAttention partitions the KV cache of each sequence into KV blocks. Each block contains the key and value vectors for a fixed number of tokens.
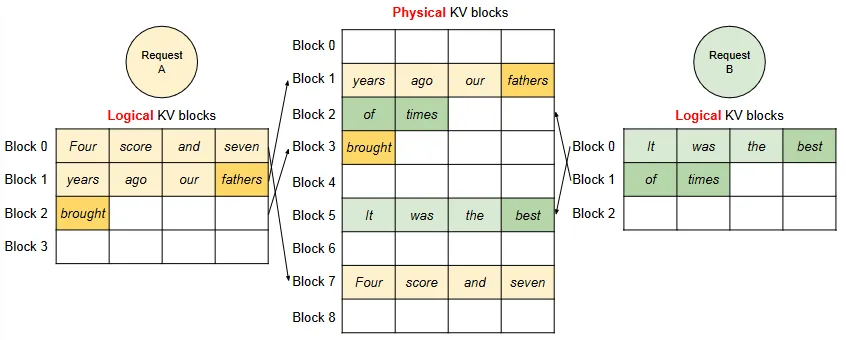 The key and value vectors are stored in non-contiguous blocks (Image taken from "Efficient Memory Management for Large Language Model Serving with PagedAttention" - Link available in the reference section)
The key and value vectors are stored in non-contiguous blocks (Image taken from "Efficient Memory Management for Large Language Model Serving with PagedAttention" - Link available in the reference section)
This change requires us to make a minor tweak to the attention calculation as well. Instead of doing the complete calculation in one go, we now have the following block-wise computation,
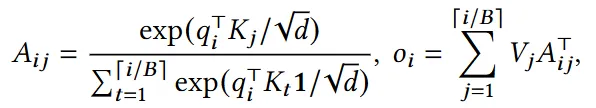
where, \(B\) -> Number of tokens in a single block (fixed)
However, a better idea is to do the following,
Create two separate functions to gather the relevant key and value vectors from the different blocks in the memory and then use them to perform attention in the traditional manner.
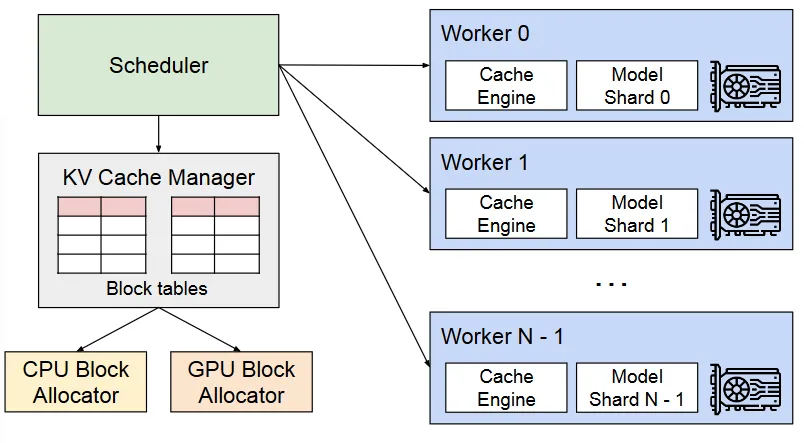 An overview of the vLLM (Image taken from "Efficient Memory Management for Large Language Model Serving with PagedAttention" - Link available in the reference section)
An overview of the vLLM (Image taken from "Efficient Memory Management for Large Language Model Serving with PagedAttention" - Link available in the reference section)
Let us now look at a complete overview of vLLM. An Operating System partitions the memory into fixed-sized pages and maps user programs’ logical pages to physical pages via a paging table. In an analogous manner, vLLM creates different logical KV blocks for a request and fills them from left to right as the new cache is generated. As apparent in the figure above, the KV cache manager maintains block tables that map the logical and physical addresses of the KV blocks for each request.
There is another neat benefit of the technique used by vLLM and that is block sharing. Since many requests in a batch share a common prefix (maybe the initial prompt), PagedAttention allows these requests to share the blocks corresponding to the common prefix. If, on the other hand, a shared prefix is followed by different tokens, a mechanism called Copy-on-Write (COW) is used.
This esentially means that the shared block is left as is; a new block is created and the block table for that specific request is updated to point to the new block.
This can be better understood by looking at the below figure,
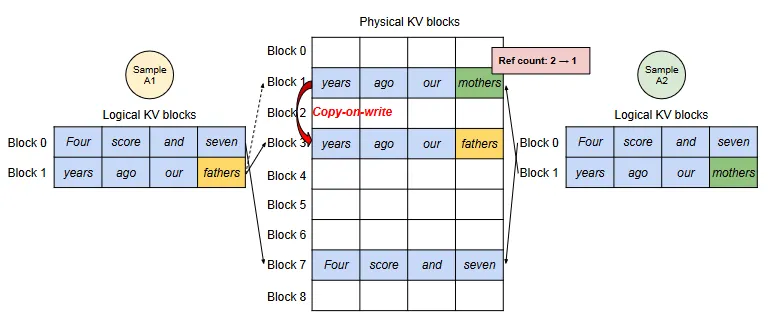 Showcasing COW using parallel sampling with samples that share a common prefix (Image taken from "Efficient Memory Management for Large Language Model Serving with PagedAttention" - Link available in the reference section)
Showcasing COW using parallel sampling with samples that share a common prefix (Image taken from "Efficient Memory Management for Large Language Model Serving with PagedAttention" - Link available in the reference section)
vLLM - V1 further improved upon this design, but we will not go into that in this article. You can read vLLM’s official blog for V1 updates.
While frameworks like TensorRT-LLM (NVIDIA), DeepSeed-Inference (Mircosoft), llama.cpp, TGI-HuggingFace, and Triton offer many different features and are also widely popular for serving LLM; in my honest opinion, vLLM is the brightest star in the world of LLM serving right now since it is open-source and provides extensive documentation. While there are improvements that are needed in the system, vLLM truly embraces the open-source environment and is a gift to us all.
References
1 - vLLM Blog - https://blog.vllm.ai/
2 - PagedAttention Paper - https://arxiv.org/pdf/2309.06180
3 - FasterTransformer Blog - https://developer.nvidia.com/blog/accelerated-inference-for-large-transformer-models-using-nvidia-fastertransformer-and-nvidia-triton-inference-server/
4 -Paging in Operating Systems - https://www.geeksforgeeks.org/paging-in-operating-system/
5 - Multi-GPU Training - https://huggingface.co/docs/transformers/main/en/perf_train_gpu_many#tensor-parallelism
6 - Survey Paper for LLM Inference - https://arxiv.org/abs/2404.14294