LoRA Can Now Make Your LLMs Multimodal!
When the LLMs came into the consumer market, everyone wanted a piece of it. However, as time has passed, we have started to yearn for more than just language modelling. Vision is one of the first modalities that we wanted to conquer, which gave rise to a lot of VLMs (Vision Language Models) coming into the market.
If I ask you the question, “I have learned to create LLM models from scratch, now I want to integrate vision into it. How do you think I should proceed?”, you will naturally give me two broad categories,
1 — Train a model from scratch that supports both language as well as vision. (Natively Multimodal Models — NMMs)
2 — Utilize the pre-trained LLM and add vision to it. (Pre-trained LLM + Vision Module)
Due to the complexities associated with NMMs, early work in the multimodal domain was done using the second approach.
Let us briefly discuss both approaches before understanding the latest developments in the field.
Natively Multimodal Models (NMMs)
Note — We will specifically be talking about “Early Fusion” models, and I will refer to NMMs as models with a shared discrete space for tokenizing all the modalities.
By referring to the above note, we can rule out some of the previous multimodal models such as VisualBERT (2019), Flamingo (2022), or PaLI (2022) for obvious reasons.
By our standards, we will say that the first truly natively multimodal model was Chameleon (2024) by Meta, which inspired the creation of the herd of Llama 4, Gemini 2.5, and others.
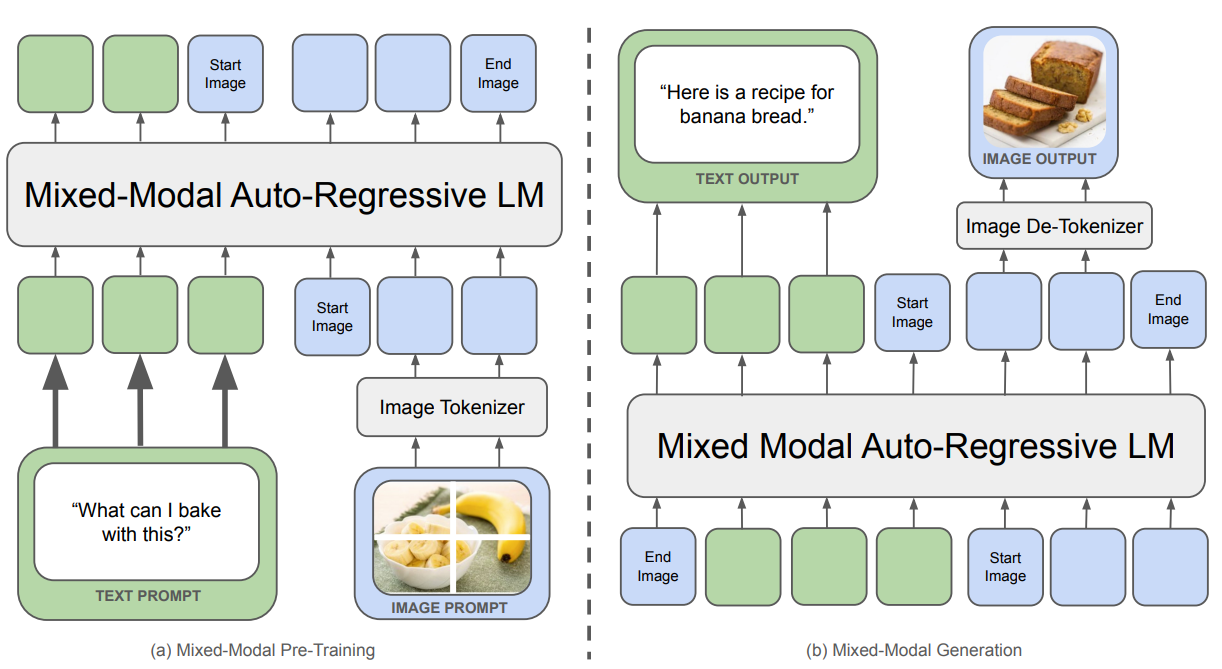
The Chameleon model largely followed the architecture presented in the Llama-2 paper, but made certain obvious tweaks, such as changing the activation function to SwiGLU and the positional encoding done using RoPE. However, the Llama architecture gave rise to the logit drift problem in Chameleon due to the translation-invariant property of the softmax.
The complete optimization steps (however, out of scope for this article) make quite an eloquent read for anyone interested in the nitty-gritty of the experimental side of creating models. I would recommend reading the entire Chameleon paper to understand how the team at Meta made these important decisions about the training and its stability.
Since we are interested in using an already existing LLM to create a multimodal model, let us move on to the second approach.
Pre-trained LLM + Vision Module
There are multiple ways to fuse an LLM with a vision module, but the most common approach is one that was demonstrated in the LLaVA paper. Let us see how that works.
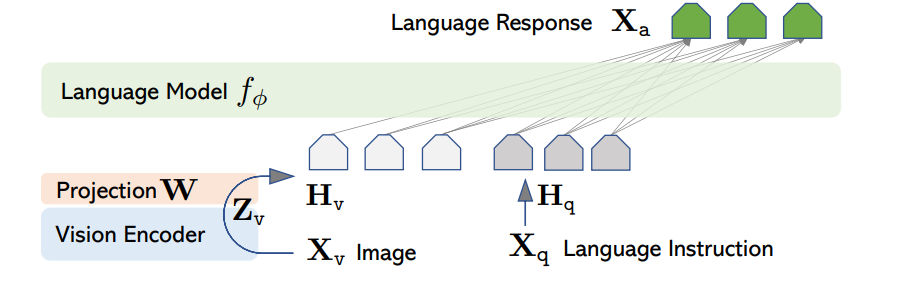
The image is passed through a vision encoder and then projected into the word embedding space. Note that this projection matrix is a trainable tensor. This encoder model can be anything — like CLIP in the LLaVA paper, or ViT (as most of the recent papers use it).
The vision encoder weights are always frozen, and the parameters of the projection matrix and the language model are updated during training.
Without getting technical at all, let us see how the training is done.
Suppose you and your assistant are at an art gallery together, and you come across a piece from the early 1900s, and you want to know more about this piece. Thankfully, your assistant knows everything about the piece, so you start having a conversation in a multi-turn fashion (where you ask a question and the assistant gives you the answer). Your assistant looks at the piece and stores the information in their memory. After that, the whole conversation is coherent, and for every question, you get an appropriate answer. The answer generation is the job of the final language model in the LLaVA architecture.
This can be reimagined to form a maximum likelihood estimate in the following fashion,
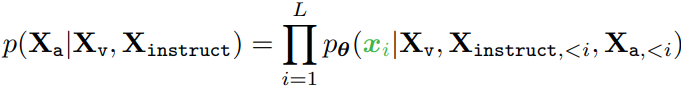
Limitations Of This Approach
While this approach is efficient in training, there are downsides to using the external vision models.
1- Image Resolution Constraints
Most vision encoders use fixed image resolutions during their training, limiting the flexibility of the images that the model can infer over.
2 — Sequential Workflow
Since there is a linear flow of data, the language model can not start its execution until the vision encoder is done with its part.
VoRA (Vision as LoRA)
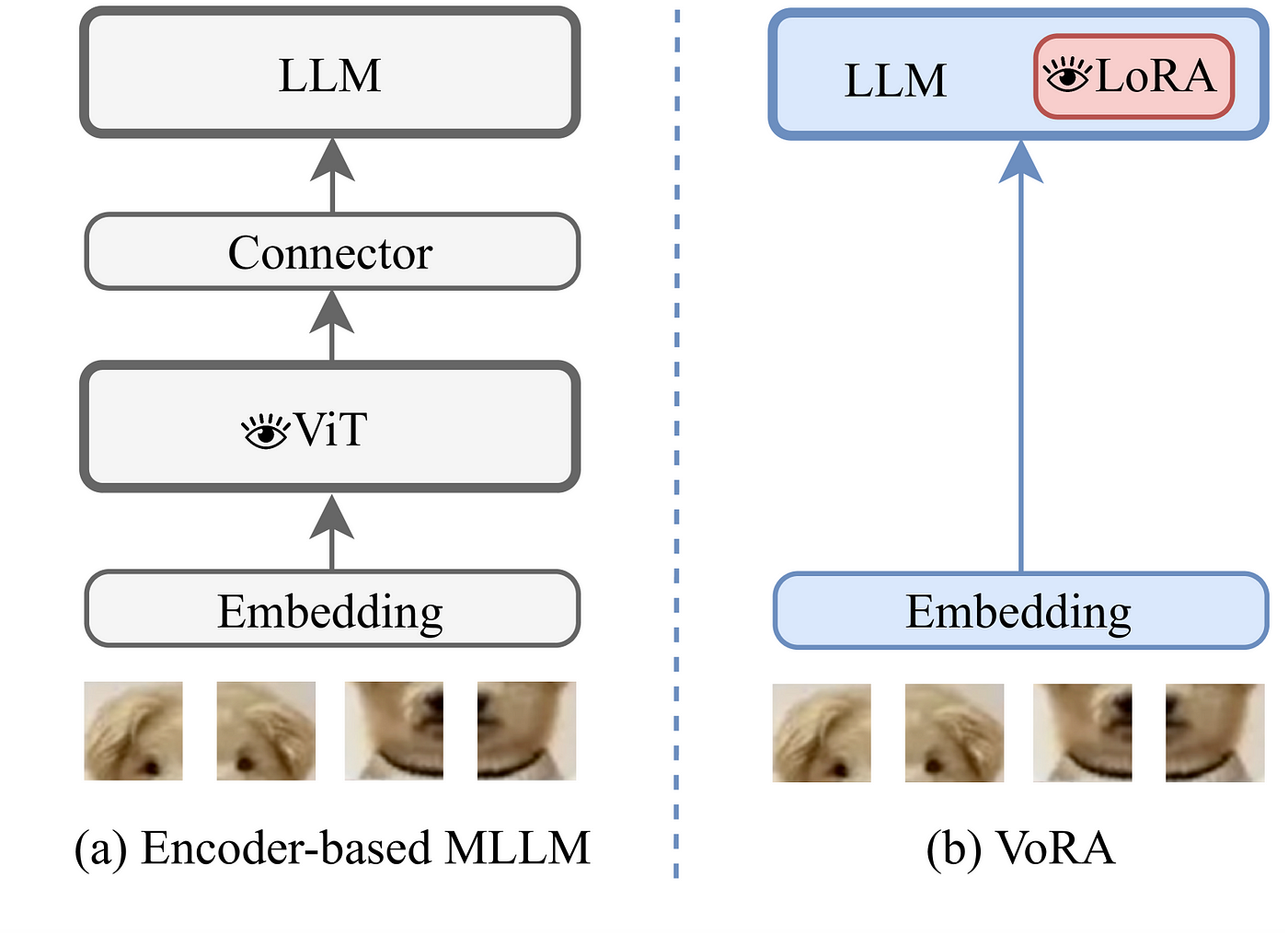
If you want to understand just the concept behind the VoRA paper, here’s a summary,
Instead of using an external vision model and putting the existing knowledge of the pre-trained LLM in harms way, VoRA proposes to keep everything frozen but the LoRA adapters (for visual context) and an embedding layer (for the images). So esentially, the LoRA adapters are the visual parameters of the model.
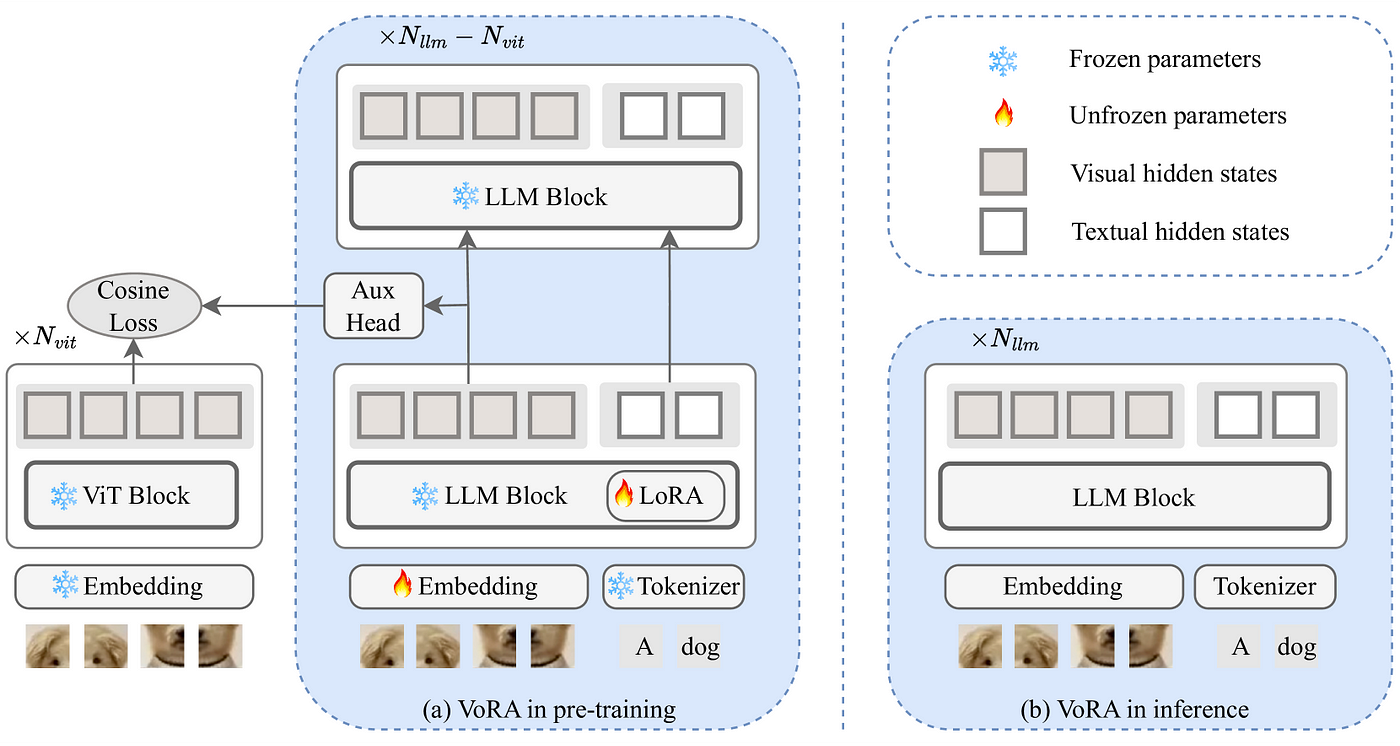
During pre-training, VoRA allows all linear layers within the first N(vit) layers to have a LoRA layer (including the QKV projections and the FFN).
After the pre-training, the LoRA parameters can be seamlessly integrated with the LLM block, thus eliminating any inference overhead.
One of the most interesting things in the paper is the knowledge distillation that is done from a pre-trained ViT model. So, for the first N(vit) layers of the LLM, the visual hidden states are aligned to the hidden states in a corresponding ViT model. This has two benefits,
1 — Accelerates training as visual knowledge is not incorporated from scratch.
2 — Only the LoRA parameters are updated instead of a complete projection layer.
The training objective of the model can then be decomposed into two components — distillation loss, and language modeling loss.
- Distillation Loss — Cosine similarity between the projected LLM features and the ViT embeddings.
- Language Modeling Loss — Cross Entropy Loss
These two losses are combined to create the final training objective.
Note — The paper is also one of the first ones discussing bi-directional attention in vision modality. It showcases a positive impact on the final model.
While still in its early stages, VoRA shows a lot of potential in creating not just VLMs, but potentially any and all kinds of MLLMs (Including audio, video, 3D image, etc). By decoupling the parameters of different modalities, thus removing the need for modality-specific parameters, we can save a lot of training time and hopefully look forward to small VLMs :)
References
1 - PaLM: Scaling Language Modeling With Pathways
2 - LLaVa Paper
3 - Chameleon Paper
4 - VoRA Paper
5 - Flamingo Paper
6 - PaliGemma Paper