You Don't Always Need An MCP Client
If you work in or around language modeling, you have most definitely heard of MCP. It is being touted as the biggest revolution in LLMs since the advent of agentic frameworks like LangGraph, crew.ai, etc.
However, most of the tutorials available still limit your usage of these MCP servers to the Claude desktop, with a mandatory need for having an MCP client that is used for communication between the host machine and the MCP server.
In this article, we will learn how to call an MCP server from any HTTP client (we will simply show how to intercept the STDIO outputs and use them). Before moving ahead, let us quickly review what MCP is and how it is beneficial for us.
Note -> You can do the same thing using the HTTP Stream Transport in MCP instead of STDIO Stream(default) but we will make it more flexible by removing the need for an MCP client altogether.
What is the Model Context Protocol (MCP)?
For those of you who want to skip this section,
By enabling LLMs to connect to arbitrary endpoints, we could shift the burden of understanding an API from a developer to an LLM. This ability to connect to arbitrary endpoints is provided to LLMs by MCP.
In November 2024, Anthropic released a blog post in which they announced that they are open-sourcing a framework that will standardize two-way connections between AI assistants and external tools. They call this standard the Model Context Protocol (MCP).
Let us look at the components of MCP (taken from the official documentation),
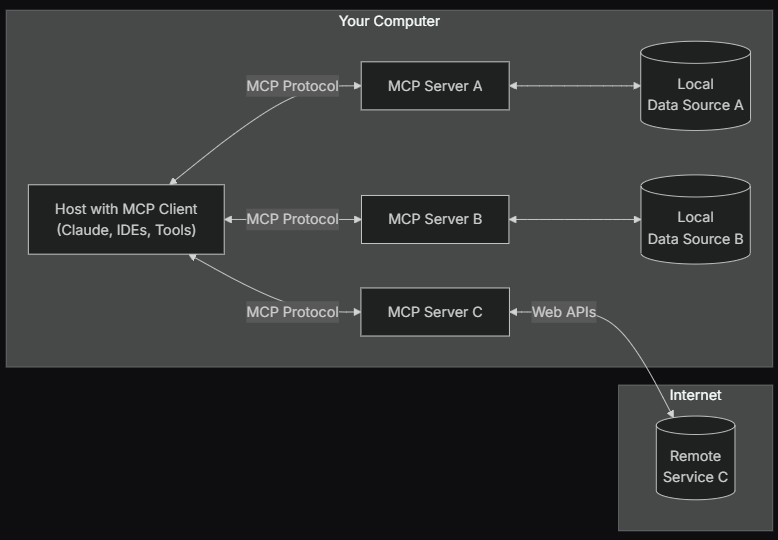
MCP Host: Programs that want to use data through MCP
MCP Client: Clients that maintain 1:1 connections with the server (We will not use this in our implementation)
MCP Servers: Programs that each expose specific capabilities through the standardized MCP
Local and Remote Services: Resources that are available either locally or through external API endpoints
Understanding the Difference Between Accessing an MCP Server Using an MCP Client and Using a Custom HTTP Client
The Model Context Protocol, by default, uses STDIO transport mechanism, which is fine for local developments and simple applications, but when we talk about web-based applications, HTTP is the preferred protocol as it allows us to have a single endpoint with session management and authentication.
MCP offers HTTP stream transport as well, but when everything you are doing is on the same machine and you don’t want to set up a server, you would want something that is simpler with zero deployment overhead.
Let us now get started with our implementation of using a custom HTTP client to connect to a MySQL MCP server!
Prerequisites
- Python (3.7+)
- Node.js (14.x or later)
- MySQL Server (8.x or later)
Setting Up The Environment
We will start by creating a separate Python environment,
# Creating the environment
conda create -n mysql_mcp
# Activating the environment
conda activate mysql_mcp
Cloning the MCP server for MySQL (https://github.com/benborla/mcp-server-mysql),
git clone https://github.com/benborla/mcp-server-mysql
cd mcp-server-mysql
Inside the repository, you will find a .env.dist file that will look like this,
# Basic MySQL connection settings
MYSQL_HOST=127.0.0.1
MYSQL_PORT=3306
MYSQL_USER=root
MYSQL_PASS=your_password
MYSQL_DB=name_of_your_db
# Additional environment variables...
Change only the MySQL connection settings and save the file as .env.
I am using XAMPP to maintain the MySQL instance, you can use any other installation of MySQL.
This is what my sample table (called “customers”) looks like:

After saving the .env file, install the Node.js dependencies inside the cloned repository, and compile the script,
npm install
# Compiling the TypeScirpt code
npm run build
Testing Out The Server By Capturing Its Response With A Subprocess
This is what my directory tree looks like right now,
mcp
|->local_app
|->.env # This .env file is identical to the one in the repo
|->cature_mcp.py
|->mcp-server-mysql # This is the cloned repo
Let us go inside subprocess.py and create a class that captures the “stdio” messages (used by the MCP server),
import subprocess
import json
import threading
class Capture:
def __init__(self, cmd=["node", # or path to your node.exe
"../mcp-server-mysql/dist/index.js"]):
self.process = subprocess.Popen(
cmd,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
bufsize=1
)
Note -> subprocess.PIPE is used to send data to the process
Here, we are simply capturing the standard input, output, and error and storing everything in a class variable named process.
Okay, now we want the following functions:
1 — Function to read standard output
# Inside the Capture class
def _read_stdout(self):
for line in self.process.stdout:
print("Stdout: ", line.strip())
2 — Function to send data to the MCP server
# Inside the Capture class
def send(self, payload):
data = json.dumps(payload) + '\n'
with self.lock: # Locking the thread
self.process.stdin.write(data)
self.process.stdin.flush() # Ensuring that the data is sent
self._read_stdout()
3 — Function to terminate the process
# Inside the Capture class
def shutdown(self):
self.process.terminate()
Let us now call these functions inside the class constructor,
# Inside the __init__ function of the Capture class
self.lock = threading.Lock()
self.reader = threading.Thread(target=self._read_stdout, daemon=True)
self.reader.start()
So, the complete Capture class looks like the following,
import subprocess
import json
import threading
class Capture:
def __init__(self, cmd=["node", # or path to your node.exe
"../mcp-server-mysql/dist/index.js"]):
self.process = subprocess.Popen(
cmd,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
bufsize=1
)
self.lock = threading.Lock()
self.reader = threading.Thread(target=self._read_stdout, daemon=True)
self.reader.start()
def _read_stdout(self):
for line in self.process.stdout:
print("Stdout: ", line.strip())
def send(self, payload):
data = json.dumps(payload) + '\n'
with self.lock: # Locking the thread
self.process.stdin.write(data)
self.process.stdin.flush() # Ensuring that the data is sent
self._read_stdout()
def shutdown(self):
self.process.terminate()
Let us test this out by using the following driver code,
# Inside the subprocess.py file
client = Capture()
# This format of this payload will be according to the MCP server
payload = {
"jsonrpc": "2.0",
"id": "1",
"method": "tools/call",
"params": {
"name": "mysql_query",
"arguments": {
"sql": "SELECT * FROM customers;" # Manual SQL query
}
}
}
client.send(payload)
The output will look like the following:
Stdout: {"result":{"content":[{"type":"text","text":"[\n {\n \"id\": 1,\n \"name\": \"Alice Smith\",\n \"email\": \"alice@example.com\"\n },\n {\n \"id\": 2,\n \"name\": \"Bob Jones\",\n \"email\": \"bob@example.com\"\n }\n]"}],"isError":false},"jsonrpc":"2.0","id":"1"}
If you don’t see this, please re-check your .env file and make sure all the environment variables are correct.
Note -> If logs are not being printed in the console, go to dist/index.js in the repo and change all the log to console.log(Except the import statement)
Bringing Everything Together
All we need to do now is have an LLM in the loop that will generate the SQL query for the MCP server to validate and execute.
In your directory tree, add a new Python file. I will call it main.py,
mcp
|->local_app
|->.env # This .env file is identical to the one in the repo
|->cature_mcp.py
|->main.py # New Python file
|->mcp-server-mysql # This is the cloned repo
In my case, I will use DeepSeek v3 directly from OpenRouter, but feel free to use any other LLM that you like.
Inside main.py, we will now write a function to prompt the LLM,
import os
from dotenv import load_dotenv
from openai import OpenAI
from capture_mcp import Capture
load_dotenv()
def llm(prompt):
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENAI_API_KEY"),
)
completion = client.chat.completions.create(
extra_body={},
model="deepseek/deepseek-chat-v3-0324:free",
messages=[
{"role": "system", "content": "You are a SQL expert. Convert natural language into SQL queries. Give only the SQL queries in the output without any addional tokens or formatting."},
{"role": "user", "content": prompt}
],
temperature=0,
)
return completion.choices[0].message.content
Note -> For replication, use the same model with the same prompt and keep the temperature equal to 0.
Now, we will create a simple while loop that will keep asking the user for input and maintain the overall workflow,
def main():
client = Capture()
try:
while True:
prompt = input("Enter your query (or 'exit'): ")
if prompt.lower() == "exit":
break
try:
sql = llm(prompt)
print("Generated SQL:", sql)
payload = {
"jsonrpc": "2.0",
"id": "1",
"method": "tools/call",
"params": {
"name": "mysql_query",
"arguments": {
"sql": sql
}
}
}
client.send(payload)
except Exception as e:
print("Error:", e)
finally:
client.shutdown()
Upon executing the main function and giving the prompt “Tell me the names of all the customers”, I get the following output,

This is exactly the same as the output we got when we wrote the query manually.
Note -> This article is not about the MySQL implementation, which can be made a lot better by passing the DB schema to the LLM beforehand, using specific fine-tuned LLMs, etc.
You can easily extend this implementation to include API endpoints and send GET and POST requests to access the MCP server. We have now successfully seen how to access MCP servers without an MCP client to make our applications more flexible and secure over the internet.