Stop treating your LLM like a black box, you MORON!
AI will soon be able to write its own code and that is inevitable. Of course, you can say — “Oh, we should build AI with caution.” but will Big Zuck listen to you? I don’t think so.
So, to save face when you tell people that you work in the field of Artificial Intelligence, I am here to teach you a little about something called Mechanistic Interpretability.
Introduction to Mechanistic Interpretability (MI)
As researchers at Anthropic define it, MI is — “an attempt to reverse engineer the detailed computations performed by transformers, similar to how a programmer might try to reverse engineer complicated binaries into human-readable source code.”
Sounds cool, right? But how will it help you? Well, instead of relying solely on crazy computing, you can actually make better models by simply understanding which particular component of your model is responsible for certain behaviors. Furthermore, it will give you the ability to enhance the guardrails for your model and make it more robust.
 Artificial Image generated by DALL-E under the prompt “A person breaking open a language model to see what’s inside”
Artificial Image generated by DALL-E under the prompt “A person breaking open a language model to see what’s inside”
A Small History of MI in the Field of Language
“Mechanistic Interpretability” is a name derived from causal mechanisms. Much like any causal system, MI was an attempt of researchers to understand the specific transformations that take place inside a neural network.
MI has long been a field of interest for researchers to refine the performance of their networks, but the term was coined by Christopher Olah, one of the co-founders of Anthropic, who, at the time, was leading an interpretability team at OpenAI.
It might be a tough pill to swallow, not so long ago, the term “machine learning” was primarily used to refer to computer vision algorithms (e.g., image classification) and so, the field of MI was mostly about feature saliency. With the advent of Transformer-based models and the rapid growth in the field of NLP, MI experts who came from a non-NLP background started showing interest in Language Models.
As a result, there have been major developments in the field of MI with libraries like TransformerLens, which can expose the internal activations of most of the SOTA open-source models.
Below is a code implementation for you to play around with,
import transformer_lens
import circuitsvis as cv
model = transformer_lens.HookedTransformer.from_pretrained("gpt2-small")
text = "Hello, I want to learn mechanistic interpretability!"
logits, activations = model.run_with_cache(text, remove_batch_dim=True)
attention_pattern = activations["attn_scores", 11, "attn"]
gpt2_str_tokens = model.to_str_tokens(text)
cv.attention.attention_patterns(tokens=gpt2_str_tokens, attention=attention_pattern)
The above code will give the following interactive output,
 Tokenized Input along with the internal activations of each head
Tokenized Input along with the internal activations of each head
We won’t go into the specifics of the above image, but if you are a seasoned researcher, you can clearly understand the importance of MI by now.
Basic Ideas in Mechanistic Interpretability
Now, we will discuss some of the fundamental ideas in MI and how you can think about a model as an amalgam of circuits,
Circuit
A circuit can be understood as a subset of a model that performs understandable calculations and maps some interpretable features into a set of new interpretable features. There are different types of circuits that have been studied, but the one we will be focusing on will be the Induction Circuits: A circuit in generative language models that deals with 2 attention heads and facilitates a form of in-context learning.
The basic functionality of an induction head is to look for previous instances of the current token and copy the next token (in case the current token was previously used). Here’s an example,
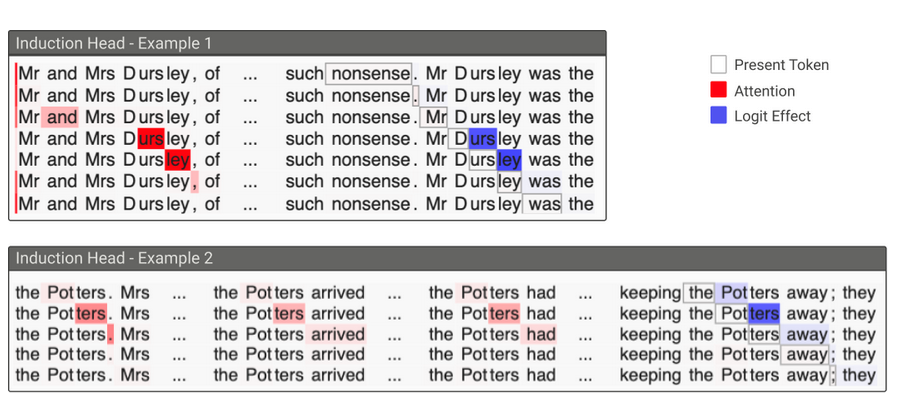 Induction heads in action (Image taken from https://transformer-circuits.pub/2021/framework)
Induction heads in action (Image taken from https://transformer-circuits.pub/2021/framework)
Here, the induction head recognizes and attends to the earlier occurrences of “Mr Dursley” (red) and ensures that the logits for predicting “Dursley” in the current context (blue) are increased.
Similarly, other circuits exist that are used for different purposes.
Intervention
In MI, one of the go-to practices to study the effect of one component is to intervene, i.e., we stop the flow of the network and alter some activation values (by either setting them to zero—pruning or by adding some noise to the activations — patching).
This forms the basis of many of the techniques in MI. We will not discuss them here, but here’s the link for an article that discusses these methods in some detail,
4 ideas that are changing the game for LLM research - Nikhil Anand
Universality
This is the hypothesis that the same circuits will appear in all the networks.
A loose interpretation of this concept might be that there is a fundamental way in which neural networks learn that goes beyond the architecture choices of a network, i.e., there exists a finite group of circuits that are fundamental to learning.
Superposition
Superposition occurs when a model is simulating a larger model, i.e., the number of dimensions available in the activation space is smaller than the number of dimensions that are interpretable. Following is an example,
Let there be only one dimension in the activation space that defines a person’s height in some contexts and the happiness level in others (two unrelated features). This shows how a network reuses the same activation dimension for entirely different purposes.
Conclusion
This article aims to highlight the importance of mechanistic interpretability along with some key concepts in the field of MI. The purpose is not to make you an expert in MI but to make you understand that treating your models like a black-box can only take you so far, and without interpretable results, you might not be able to improve your networks efficiently.
In future articles, I will be discussing individual concepts of mechanistic interpretability in greater detail. Stay tuned! References
1 — https://transformer-circuits.pub/2021/framework/index.html
2 — https://distill.pub/2020/circuits/zoom-in/
3 — https://arxiv.org/html/2410.09087v1
4 — https://github.com/TransformerLensOrg/TransformerLens/tree/main